
Open Source für Big Data
Open Source als Alternative zu Standardanwendungen
Ob Python, Hadoop oder Spark – Open Source im Big-Data-Umfeld ist Enterprise-ready! Wir unterstützen unsere Kunden bei Evaluierung, Installation, Entwicklung, Betrieb und Wartung.
Neben den etablierten Standardtechnologien nimmt Open Source eine immer gewichtigere Rolle ein – auch bei Big Data. Frei verfügbare Software ist längst aus den Kinderschuhen herausgewachsen und eine echte Alternative für Datenspeicherung, -verarbeitung und -auswertung. Für Unternehmen gilt es daher zu klären, welche Software für ihre Zwecke die passende ist, wie der interne Know-how-Aufbau sichergestellt wird, und wie die Integration in bestehende Prozesse gelingt.
Wir wissen um die Vorzüge von offenen IT-Anwendungen: Open -Source-Software für Big Data ist ausgereift. Sie steht nicht nur bei jungen IT-Spezialisten hoch im Kurs, sie bietet vor allem Flexibilität. Denn Unternehmen müssen sich nicht an einen bestimmten Anbieter binden und können direkt loslegen. Die Installation ist in vielen Fällen kostenfrei und trotzdem Enterprise-ready. Viele Produkte bieten auch optionalen Support mit professioneller Wartung.
Support gibt es natürlich auch von uns: Wir evaluieren Open-Source-Produkte und helfen dabei, die richtigen Lösungen auszuwählen und zu implementieren – egal ob als Kombination mit bestehenden Systemen oder Stand-Alone. Über den gesamten Software Life Cycle hinweg unterstützen wir als Partner unter anderem bei Updates, Migrationen in die Cloud oder bei Wartung und Wissenstransfer.

Open Source bietet vielfältige Möglichkeiten. Wir beraten Sie gerne hierzu.
Sie möchten sich ein Bild darüber machen, wie Open-Source-Anwendungen im Big-Data-Bereich aufgebaut sein können? Dann lesen Sie hier mehr über unsere eigene, auf Open-Source-Lösungen basierte Plattform VDPP. Sie ist eine Blaupause, mit der wir gerne auch mit Ihnen in einen Proof of Concept oder eine Zusammenarbeit gehen.
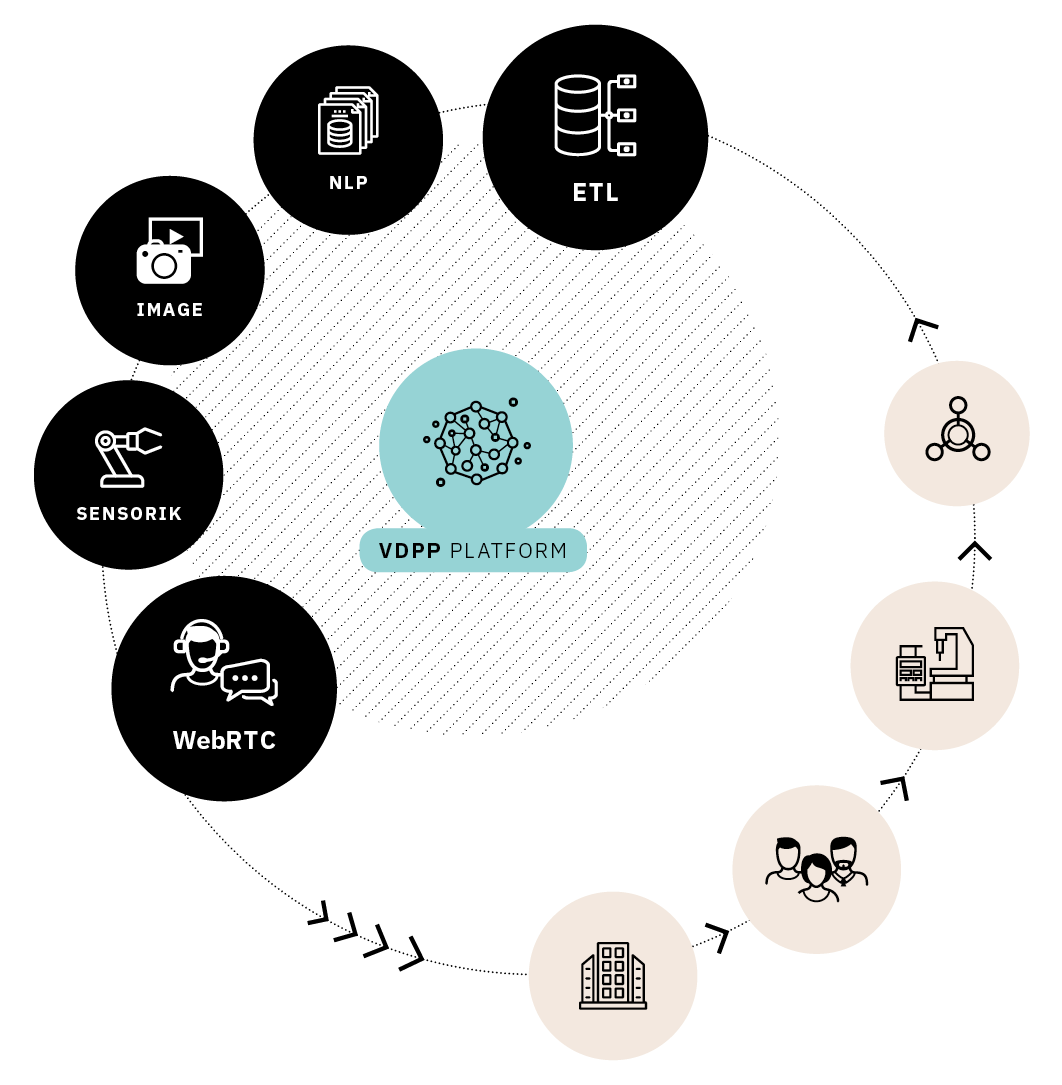
Unsere VDPP-Plattform baut auf Open Source auf. Hier erfahren Sie mehr.
Die Vorteile auf einen Blick
Beim Einsatz von Open Source durch unsere Experten können Sie… |
|
Warum sind wir die Richtigen beim Thema Open Source? |
|
Schon immer begeistern wir uns für die neuesten Big Data-Technologien und -Lösungen, deren Umsetzung und praktische Nutzung. Wir sind ein wissbegieriges Team, das in vielen Prototypen, Projekten und eigenen Entwicklungen Open-Source-Know-how sammelt – immer wieder aufs Neue. Und wir bleiben begeistert und interessiert. Dank dem Lerneifer und unserer Praxiserfahrung können unsere Kunden bei jedem Open-Source-Vorhaben auf uns bauen. |
Unser Wissen reicht von Programmiersprachen über Open-Source-Plattformen hin zu NoSQL-Datenbanken. Ein Einblick: |
Sprachen
- Python
- Java
- R
Big Data Plattformen
- Cloudera Distribution for Hadoop (CDH)
- Hortonworks Data Platform (HDP)
Big Data
- Spark
- Hive
- Kafka
- Dask
Data Science und Analytics
- Pandas
- NumPy
- TensorFlow
- scikit-learn
NoSQL Datenbanken
- MongoDB
- HBase
- Neo4j
Neben Open Source für Big Data kennen wir auch Handwerkszeug wie
- Docker
- Git
- Jenkins
Sie wollen mehr erfahren? Wir freuen uns auf Sie.

Der studierte Informatiker besitzt ein breites IT-Spektrum und -Wissen: angefangen bei Architekturen bis hin zu Business Analysen. In seiner langen Karriere hat er bereits in allen Branchen erfolgreiche Projekte durchgeführt. Er ist immer gerne mit dabei, wenn es darum geht, Kunden zu beraten, sich in neue Themenkomplexe einzuarbeiten und gute Lösungen zu erstellen.